
티스토리 뷰
배열
배열

배열(Array) : 데이터(원소; element)를 메모리 상에 연속하게 배치하여 논리적 / 물리적 구조가 일치하는 선형 자료구조
- 동일한 자료형의 원소들만 저장 가능
- 인덱스(index ; 순서값) 를 통해 O(1)라는 빠른 시간 내에 idx 번째 원소에 접근 / 변경할 수 있음
- 연속한 메모리 주소를 필요로 하므로, 원소의 자료형과 크기가 정해지면 변경할 수 없음
- 캐시 메모리 적중률 이 높아 최적화 성능이 우수함
◆ 캐시 메모리 적중률(cache hit rate)
컴퓨터는 자주 이용할 것 같은 자료를 캐시 메모리(Cache memory) 라는 공간에 따로 저장하여 성능을 향상시키는데, 적중률 이란 캐시 메모리에 저장되어 있을 확률을 의미한다. 적중률이 높기 위한 3가지 조건을 지역성(locality)의 원리 라고 한다.
자료구조들은 대부분 순차적 지역성을 만족하며, 특히 배열은 연속된 메모리 공간을 이용하여 공간 지역성을 만족하므로 높은 캐시 메모리 적중률을 보인다.
- 시간 지역성 : 최근에 사용된 자료가 다시 참조될 확률이 높다.
- 공간 지역성 : 특정 메모리 및 그 주변의 자료가 다시 참조될 확률이 높다.
- 순차 지역성 : 메모리에 저장된 순서대로 다시 참조될 확률이 높다.
◆ 논리적 구조 / 물리적 구조
자료구조를 개념적으로 구현한 추상적 구조를 논리적 구조, 메모리 상에 실제 저장되는 형식을 물리적 구조라고 한다.
▼ index가 0부터 시작하는 이유
0 - based indexing (numbering)
배열은 원소의 자료형이 정해져 있고 메모리를 연속적으로 할당하기 때문에, 시작 데이터의 메모리 주소값만 알면 원소의 용량에 순서(index)값을 곱한 값을 이용하여 다음 데이터들의 주소를 계산할 수 있다. 이 값을 일관성 있게 계산하려면, "메모리 주소값 + (용량 x 순서값)"이라는 수식을 사용하되 순서값을 0부터 시작하면 된다.
즉 , index 값이 0부터 시작할 때 일관성 있는 프로그래밍이 가능하기 때문에 0부터 시작하는 것이다. 이는 C언어 의 전신인 BCPL 부터 유구하게 이어내려져 온 전통이기도 한데, 이 규칙을 따르지 않던 구세대 언어(Fortran, Algol)등이 사장되었다는 점에서도 그 당위성을 더해준다.
Dijkstra의 의견
Dijkstra 는 1982년 [include, exclusive) 구간 표현에 대한 의견을 제시했는데, 이를 요약하면 아래와 같다.
- 어떤 구간을 표현할 때는 [a,b)방식이 좋다. 그 이유는 시작 수와 마지막 수의 차가 구간의 크기와 같고, 두 구간을 더할 때 마지막 수와 시작 수가 같아 깔끔하기 때문이다.
- 시작점이 열린 구간인 (a,b]와 (a,b)는, 구간의 최솟값보다 작은 수를 포함해야 하므로 깔끔하지 않다. 예를 들어 자연수를 표기하기 위해선 (0,N] 으로 표기해야 하는데, 0을 초과하는 시작 지점이 정확히 어디인지 알 수 없다.
- [a,b] 방식은 공집합을 표현할 수 없거나, a > b로 표현해야 하므로 깔끔하지 않다.
- 따라서 N개의 구간을 [a,b) 방식을 사용할 때는 [0,N)으로 깔끔하게 표현할 수 있다. 이런 이유로 0이야말로 가장 자연스러운 수이며, 자연수로 취급해야 한다.
현대 프로그래밍의 구간표현(예를들면, java나 python의 slice 메서드 등)역시 대부분 위와 같은 방식을 따르고 있다.
다차원 배열
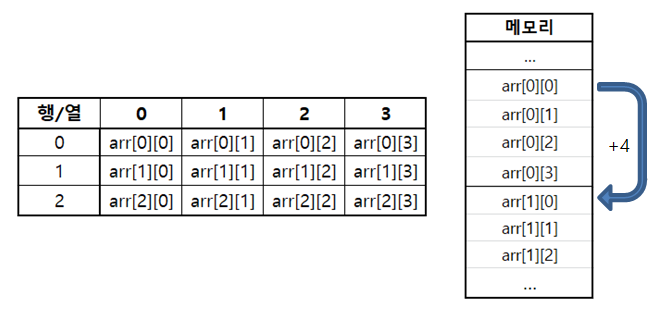
배열의 원소가 또 다른 배열인 배열로, 행렬(matrix)과 유사한 형태를 띄어 각 index를 행(row), 열(column)으로 구분하기도 함
◆ Java의 다차원 배열과 메모리
Java의 다차원 배열에서 같은 행의 배열값은 연속된 메모리를 차지하게 할당되지만, 각 행의 배열들의 주소 자체는 heap 메모리 영역 곳곳에 배치하게 된다. 쉽게 말해 1차원 배열과는 달리 서로 다른 행끼리 사칙연산을 통한 메모리 주소값을 얻는 것은 불가능하다.
Java의 다차원 배열은 논리적 구조와 물리적 구조가 동일하지 않으며, 메모리 주소(참조값)연산으로 다른 행의 원소에 접근할 수 없다.
※ 우리는 일반적으로 좌표 평면의 x,y 방향 체계 에 익숙해져 있으며, 2차원 배열은 그 구조상 좌표 평면과 유사하게 사용가능하다.
그러나 2차원 배열의 논리적 구조는 세로방향(행; y방향) -> 가로방향(열;x방향)으로 진행되기 때문에 익숙하지 않을 수 있다. 즉, 우리가 아는 좌표 평면 방식으로 표기한다면 arr[y][x]가 되기 때문에 헷갈릴 수 있음에 유의하자.
배열과 복잡도
시간복잡도
접근 / 변경 : O(1)
- 인덱스를 이용해 해당 데이터에 바로 접근하고 변경할 수 있음
삽입 / 삭제 : O(1) ~ O(N)
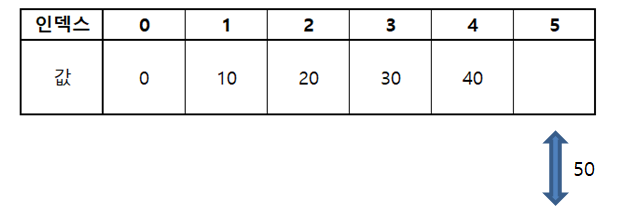
- 배열의 맨 끝에 데이터를 삽입하거나 삭제할 경우 원소의 이동이 일어나지 않아 O(1) 소요

- 배열의 중간에 데이터를 삽입하거나 삭제할 경우 원소의 이동이 최대 N번 일어날 수 있으므로 O(N) 소요
공간복잡도
O(N) : 배열은 일반적으로 별다른 추가 메모리(Overhead)공간을 필요로 하지 않음
Java 배열
Arrays
Java는 참조 자료형으로 배열을 구현하고 있으며, Arrays 클래스 에서 정렬 등 다양한 연산을 지원
행렬 리터럴 을 이용하여 각 행의 열 갯수가 동일하지 않은 비정방형 다차원 배열 선언 가능
int[] arr = new int[5];
// 1차원 배열의 선언
int[][] arr2 = new int[5][4];
// 다차원 배열(예시는 2차원)의 선언
int[][] arr3 = {{1,2,3}, {4,5}};
// 비정방형 배열 선언가능유용한 메서드
정렬
int[] arr1 = {1,3,2,4,5};
Arrays.sort(arr1); // 기본 정렬
Arrays.parallelSort(arr1); // 멀티쓰레드 기반 정렬(Java8 이상)
// 정렬결과 : {1,2,3,4,5}
int[][] arr2 = {{2,3}, {1,4}};
Arrays.sort(arr2, (a, b) -> a[0] - b[0]); // 2차원 이상 정렬
// 정렬결과 : {{1,4}, {2,3}}
Arrays의 sort 메서드는 기본적으로 퀵정렬 방식으로 정렬하며, 1차원 배열의 정렬만을 지원한다.
만약 다차원 배열이거나 내부의 자료형이 단순 크기 비교가 안되는 경우엔 2번째 인자로 Comparator 객체를 받아서 원하는 방식으로 정렬할 수 있으며, APS에서는 보통 람다식을 이용하여 사용한다.
탐색
int[] arr = {1,3,5,6,7,8,9};
int idx = Arrays.binarySearch(arr,5); // 이분탐색
// index는 2Arrays 클래스는 이분탐색을 지원하며, 이를 통해 빠르게 특정 값을 찾을 수 있다.
복사
int[] arr = {1,2,3,4,5};
int[] copy = Arrays.copyOf(arr, arr.length); // 복사 : {1,2,3,4,5}
int[] copy2 = Arrays.copyOfRange(arr, 1,4); // 구간복사 : {2,3,4}
복사하고 싶은 길이, 또는 구간을 설정하여 배열을 복사할 수 있으며, 깊은 복사가 필요할때 유용하게 사용할 수 있다.
채우기
int[] arr = new int[5];
Arrays.fill(arr, 10); // 채우기 : {10,10,10,10,10};배열을 특정값으로 채운다. 반복문 등에서 배열을 새롭게 선언하지 않고 초기화할 때 유용하다.
출력
int[] arr = {1,2,3};
System.out.println(Arrays.toString(arr)); // 출력 : "[1,2,3]"
int[][] arr2 = {{1,2}, {3,4}};
System.out.println(Arrays.deepToString(arr2)); // 출력 : "[[1,2],[3,4]]"
다차원 배열의 경우 deepToString을 이용하지 않으면 내부 배열은 참조값 주소가 출력된다.
테스트를 할 때 중간값을 측정해야 하는 경우 많이 사용된다.
비교
int[] arr1 = {1, 2, 3};
int[] arr2 = {1, 2, 3};
boolean result = Arrays.equals(arr1, arr2); // true
int[][] arr1 = {{1,2}, {3,4}};
int[][] arr2 = {{1,2}, {3,4}};
boolean result = Arrays.deepEquals(arr1, arr2); // true다차원 배열을 주소값이 아닌 값으로 비교하려면 deepEquals를 사용해야 한다.
테스트 케이스 확인 등에 유용하게 사용된다.
- 최종 수정일 : 25-03-20
- 이 글은 지속적으로 수정되고 있으며, 오타나 잘못된 정보에 대한 사항은 댓글로 남겨주시면 감사하겠습니다.
'APS > 이론' 카테고리의 다른 글
| [APS] 이론 : 투포인터 (0) | 2025.03.21 |
|---|---|
| [APS] 03 : 자료구조 - 동적 배열 (0) | 2025.03.20 |
| [APS] 01 : 자료구조 개론 (0) | 2025.03.19 |
| 투포인터 - 1 (0) | 2025.02.17 |
| [APS] 입출력 : Buffered 시리즈 (6) | 2024.12.29 |
- Total
- Today
- Yesterday
- db의 역사
- SQL
- DBMS
- 데이터베이스
- 입출력
- dialect
- 필드
- BufferedReader
- 알고리즘
- BufferedWriter
- StringBuilder
- 배열
- db오브젝트
- DB
- 레코드
- APS
- Scanner
- 테이블
- oracle
- 자료구조
- Java
- SQL이란
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |